Salutojn al ĉiuj legantoj de la blogo!
Mi pensas, ke tiuj, kiuj ofte laboras ĉe la komputilo (ne ludas, nome laboras), devis trakti tekstan agnoskon. Nu, ekzemple, vi skanis eltiraĵon el libro kaj nun vi devas enmeti ĉi tiun parton en vian dokumenton. Sed la skanita dokumento estas bildo, kaj ni bezonas tekston - por tio ni bezonas specialajn programojn kaj interretajn servojn por rekoni tekston el bildoj.
Pri agnoskaj programoj, mi jam skribis en antaŭaj afiŝoj:
- tekstoskanado kaj agnosko en FineReader (pagita programo);
- Labori en analoga FineReader - CuneiForm (senpaga programo).
En la sama artikolo, mi ŝatus restadi pri interretaj servoj por teksta agnosko. Finfine, se vi bezonas rapide ekhavi tekston kun 1-2 bildoj - tute ne gravas ĝeni instali diversajn programojn ...
Grava! La kvalito de agnosko (nombro de eraroj, legebleco, ktp.) Tre dependas de la originala kvalito de la bildo. Tial, kiam skanas (fotado, ktp), elektu la kvaliton kiel eble plej alte. Plej ofte, kvalito de 300-400 dpi sufiĉos (dpi estas parametro, kiu karakterizas bildan kvaliton. En la agordoj de preskaŭ ĉiuj skaniloj, ĉi tiu parametro kutime estas indikita).
Interretaj Servoj
Por montri kiel funkcias la servoj, mi prenis ekrankopion de unu el miaj artikoloj. Ĉi tiu ekrankopio estos alŝutita al ĉiuj servoj, kies priskribo estas prezentita sube.
1) //www.ocrconvert.com/

Mi tre ŝatas ĉi tiun servon pro ĝia simpleco. La retejo, kvankam anglalingve, sed funkcias bone kun la rusa lingvo. Ne necesas registriĝi. Por komenci agnoskon, vi devas fari 3 agojn:
- alŝutu vian bildon;
- elektu la lingvon de la teksto, kiu estas en la bildo;
- premu la butonon de rekono.
Subteno por formatoj: PDF, GIF, BMP, JPEG.
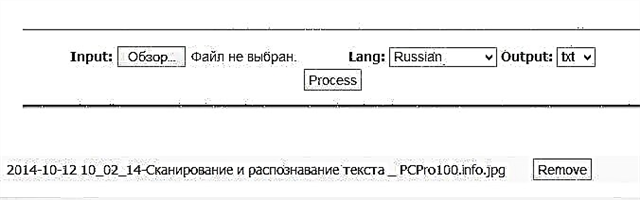
La rezulto estas prezentita sube en la bildo. Mi devas diri, la teksto estas sufiĉe bone rekonita. Krome tre rapide - mi atendis laŭvorte 5-10 sekundojn.

2) //www.i2ocr.com/
Ĉi tiu servo funkcias simile al ĉi-supre. Ĉi tie vi ankaŭ devas elŝuti la dosieron, elekti la agnoskan lingvon kaj alklaki la ĉerpan tekstbutonon. La servo funkcias tre rapide: 5-6 sekundoj. unu paĝo.
Subtenataj formatoj: TIF, JPEG, PNG, BMP, GIF, PBM, PGM, PPM.

La rezulto de ĉi tiu interreta servo estas multe pli oportuna: vi tuj vidas du fenestrojn - en la unua, la rekono-rezulto, en la dua - la originala bildo. Tial estas facile fari redaktojn dum vi redaktas. Parenteze, registriĝi kun la servo ankaŭ ne necesas.

3) //www.newocr.com/

Ĉi tiu servo estas unika laŭ pluraj manieroj. Unue ĝi subtenas la "novanfangledan" formaton DJVU (por iu kompleta listo de formatoj: JPEG, PNG, GIF, BMP, TIFF, PDF, DjVu). Due, ĝi subtenas la elekton de tekstaj areoj en la bildo. Ĉi tio tre utilas, kiam vi havas ne nur tekstojn en la bildo, sed ankaŭ grafikajn areojn, kiujn vi ne bezonas rekoni.
La agnoska kvalito estas pli alta ol ne necesas registriĝi.

4) //www.free-ocr.com/

Tre simpla servo por rekono: alŝutu bildon, precizigu la lingvon, eniru captcha (por la fino, la sola servo en ĉi tiu artikolo, kie fari tion), kaj premu la butonon por traduki la bildon en tekston. Efektive ĉio!
Subtenataj formatoj: PDF, JPG, GIF, TIFF, BMP.

La agnoska rezulto estas meza. Estas eraroj, sed ne multaj. Tamen se la kvalito de la originala ekrankopio estus pli alta, estus ordo de grando malpli da eraroj.

PS
Tio estas ĉio por hodiaŭ. Se vi konas pli interesajn servojn por teksta agnosko - dividu en la komentoj, mi estos dankema. Unu kondiĉo: estas dezirinde, ke vi ne bezonas registriĝi kaj la servo senpaga.
Ĉion plej bonan!